VideoBERT
C. Sun et al.
Google Research
Presented by: Nikhil Devraj
MSAIL
Motivation
- Representations of video data generally capture only low-level features and not semantic data

- BERT performs really well on language modeling tasks
Contributions
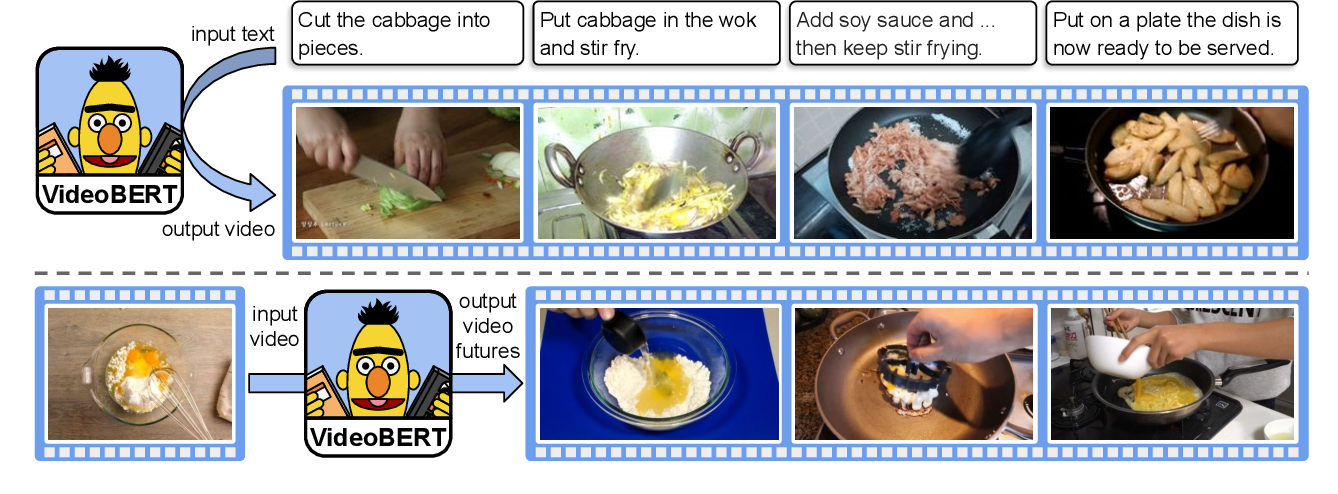
- Combined ASR, Vector Quantization, and BERT to learn high-level features over long time spans in video tasks
- A first step in the direction of learning high-level joint representations
Background
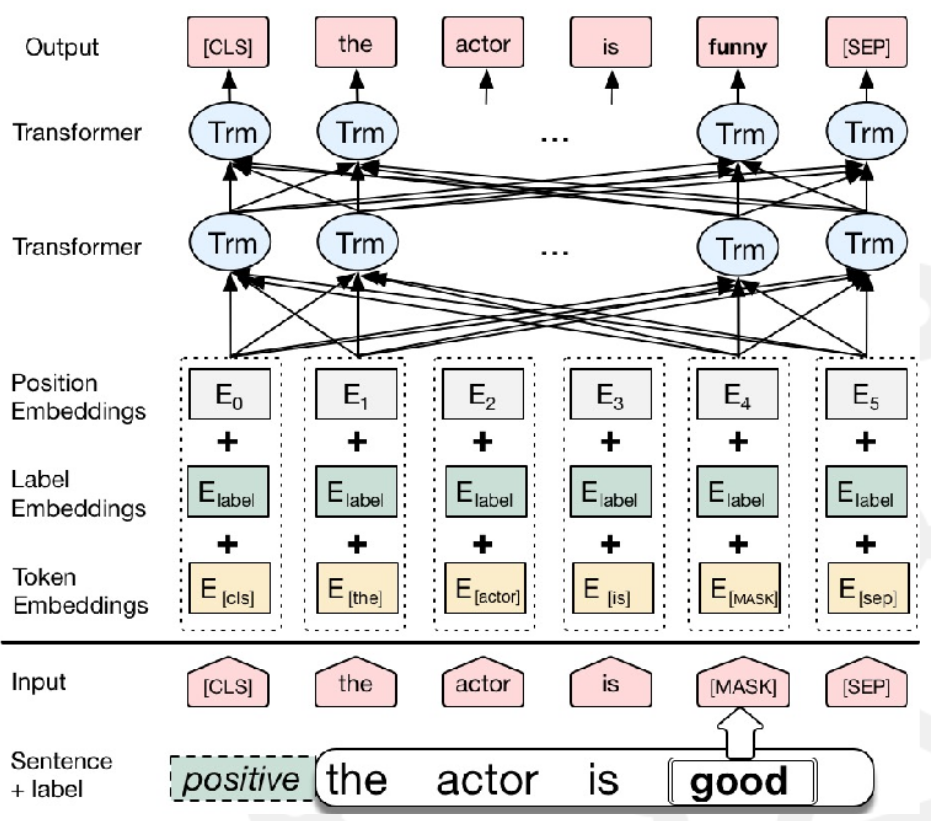
BERT
- Pretrained language model used to generate a probability distribution of tokens
- Obtained by training model on “masking” task
Supervised Learning
- Expensive to get labeled data
- Short term events in video data
Unsupervised Learning
- Learns from unlabeled data
- Normal approaches used latent variables (i.e. GAN, VAE)
- differ from BERT
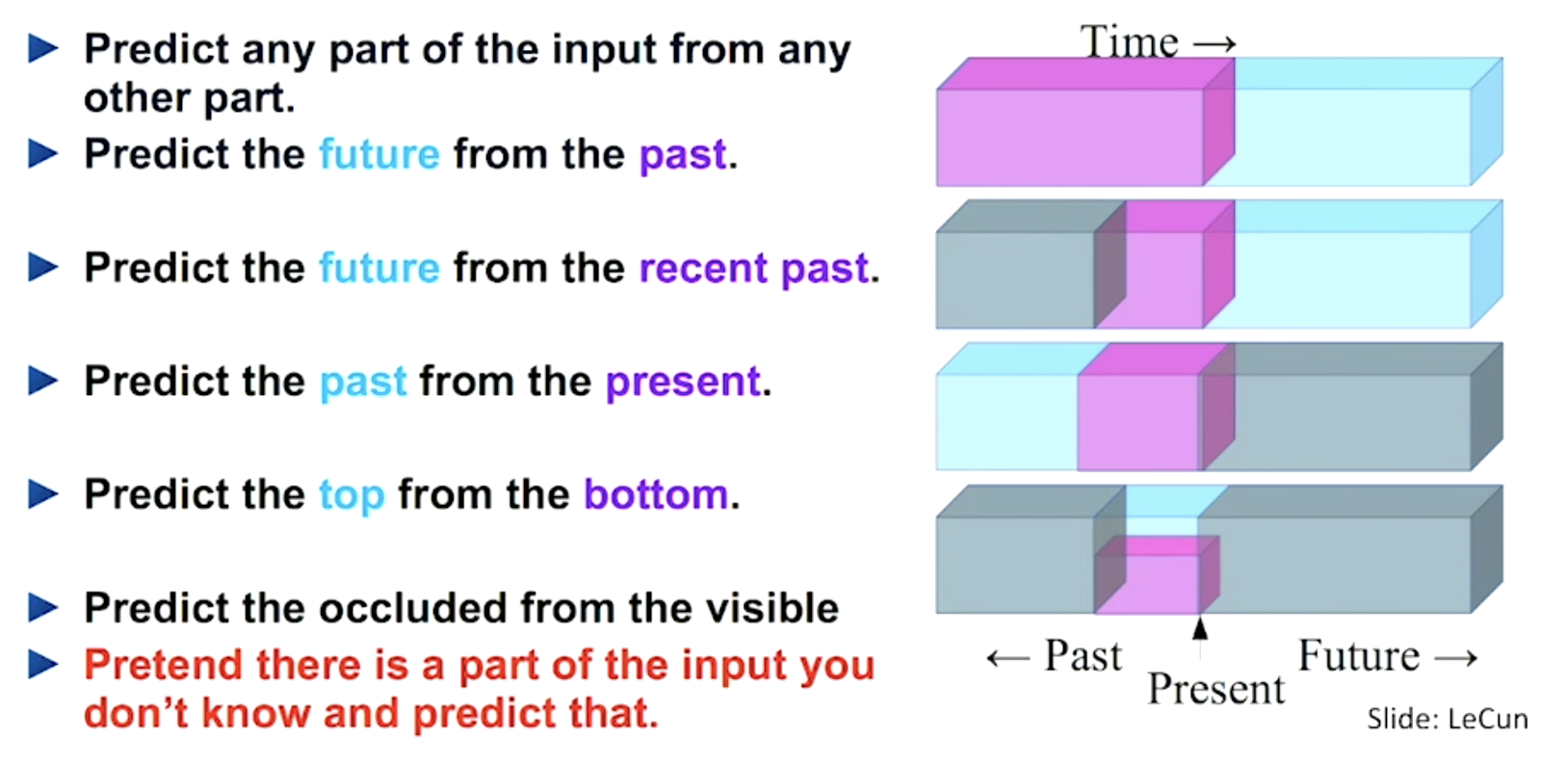
Self-supervised Learning
Cross-Modal Learning
- Synchronized audio and visual signals allow them to supervise each other
- Use ASR as a source of crossmodal supervision
Instructional Video Datasets
- Papers used LMs to analyze these videos with manually provided data
- Datasets were too small
Method
Omitted the rest
You get the principles I’m getting at though right?