Using Transformers for Vision
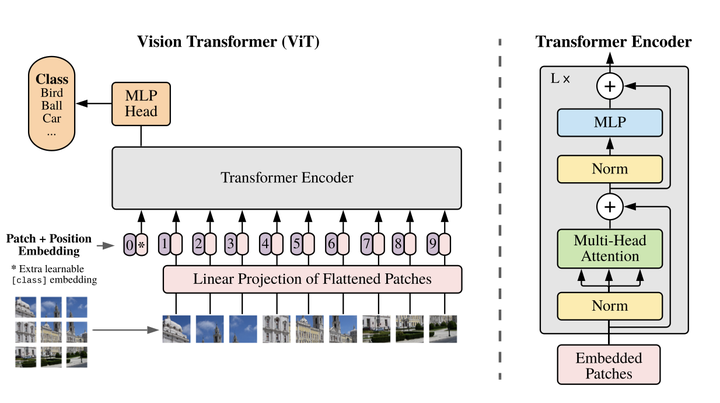 Credit: Dosovitskiy et al.
Credit: Dosovitskiy et al.
Speaker(s): Andrew Awad and Drake Svoboda
Topic: Using Transformers for Computer Vision
In recent years we’ve seen the rise of transformers in natural language processing research, burgeoning the field to incredible heights. However, these very same transformers were seldom applied to computer vision tasks until recently. Andrew and Drake discussed how transformers have been used in vision tasks in recent years in a presentation covering two papers. The first, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (via Google Brain), is the “Attention is All You Need” of vision. Namely, this paper covers how one can construct a vision architecture devoid of the commonly applied CNN and still achieve comparable or better performance results while possibly cutting down computing resources. The second paper, End-to-End Object Detection with Transformers (via FAIR), formalizes the object detection task in a unique way that affords the usage of transformers.
Supplemental Resources
Papers:
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE