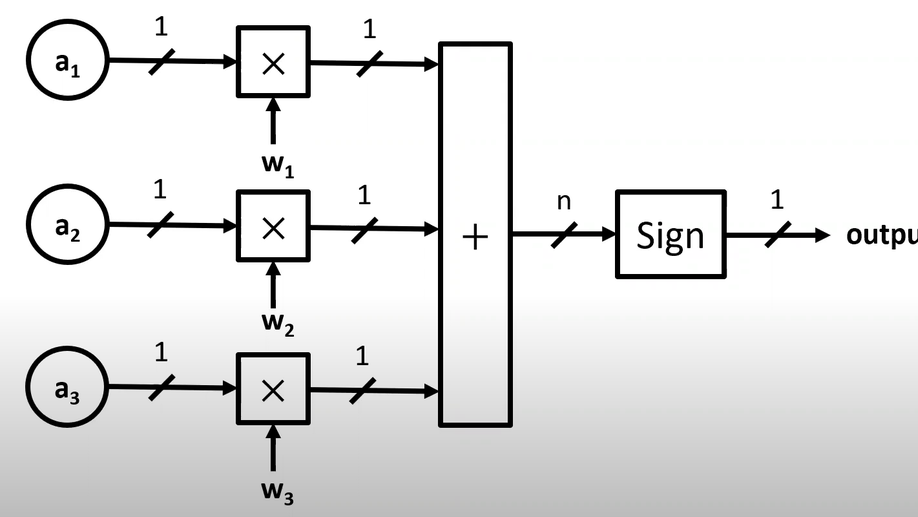
Michigan Student Artificial Intelligence Lab
A student organization focused on exploring cutting-edge artificial intelligence education, application and research.
A student organization focused on exploring cutting-edge artificial intelligence education, application and research.
MSAIL is a student organization devoted to artificial intelligence research. We strive to spread our passion for artificial intelligence throughout the University of Michigan student body, regardless of demographic or academic standing. As of Winter 2024, our main operations are education, projects, and reading groups.


Check out our education tracks and join our slack for session updates.
We are graciously sponsored by the Michigan Institute for Data Science (MIDAS).
Also, be sure to check out our sister organization, the Michigan Data Science Team (MDST)!